Dear community,
I am using openLCA 2.0.4 and the EF 3.1 database as well as ecoinvent cutoff 3.9.1 for my research. I only use LCIA methods that are contained within the database.
My question is about the LCIA checks tab in general.
Now, when running the LCIA for a dataset like eg. PE granulates from EF 3.1 (with EF3.1 LCIA), i checked the LCIA checks tab in the results section and i expected the "uncovered flows" to be empty, because i thought that all the elementary flows inside the dataset should have a corresponding characterization factor. Now, I realized that there is a really long list of flows that are not covered by the selected LCIA method. (See image)
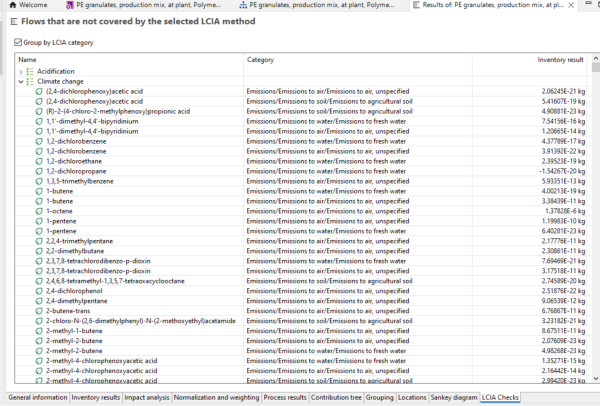
Now my hypothesis was initially that maybe this has to do with the immaturity of the EF 3.1 database, but also when I run the analysis in ecoinvent in the same way with some arbitrary other dataset, the list of flows is also very long.
I think i realized now why this is the case: eg. cadmium (Emissions/Emissions to water/Emissions to fresh water) is in the list for uncovered flows of the GWP category, because it does not have a chracterization factor in that specific impact category, but for others (Ecotoxicity and Human toxicity).
Now what I want to get your thought on: What is actually the idea how the LCIA checks tab can be useful to see if my LCIA method is complete? If elementary flows that simply belong to another impact category are listed as uncovered in all other categories, then there will just be an endlessly long list of flows, where I cannot identify, which entries are problematic (and are actually not mapped correctly) and which are only there for the above mentioned, well understandable reason?
I hope my formulations are understandable.
Thanks and see you soon,
Paul
