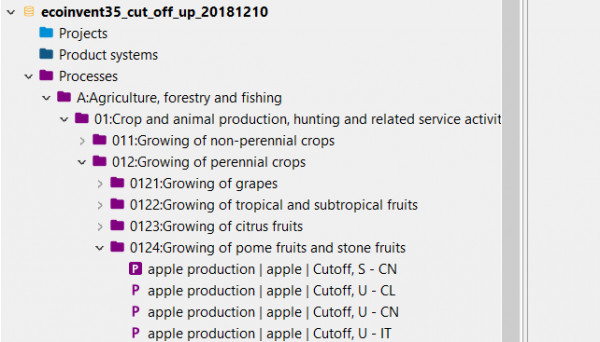
Not sure if I missed something but as far as I can see, equivalent processes in ecoinvent UP/LCI have different UUIDs e.g.:
apple production | apple | Cutoff, U - CN: de20bbdb-364a-30c9-8ee3-14fd22173a80
apple production | apple | Cutoff, S - CN: de4cf6f5-3765-3ae7-a81a-9d6774f777a1
Therefore, you can simply import LCI processes in the UP-based version of ecoinvent.
If for some reason, the UUIDs are the same, you can also assign a new UUID (although this is not really recommended as the chance to cause some problems is probably higher than to actually solve a problem). Maybe you can do this with LCI processes that you want to import as they do not really have links anyway but do not do it with unit processes as the links won't work anymore and definitely create a backup of your database before. And again, this is experimental and not really a recommended practice. Be extremely careful.
Window -> Devloper tools -> SQL
UPDATE TBL_PROCESSES SET REF_ID='NEW UUID' WHERE REF_ID='OLD UUID';
Click on the run button in the top-right corner. Done
Generate UUIDs e.g. via Excel or https://www.uuidgenerator.net/.
